Apache Flink在2014年自apache孵化器畢業, 是一款由Java和Scala開發的計算框架, 可處理批次資料(Batch)和流式資料(Streaming), 目前主要由data Artisans的成員進行開發。
Data Artisans官方網站, 將目前處理streaming data的主要框架進行比較, 此處只有Spark Streaming為Micro-batch處理streaming data, 其他框架為原生streaming式的框架, 這點反映在Latency上面, 相對的, Throughput也是Spark Streaming最佳。此外, Apache Flink有保證Exactly once的模式, 並有狀態紀錄和不同時間窗格的應用。
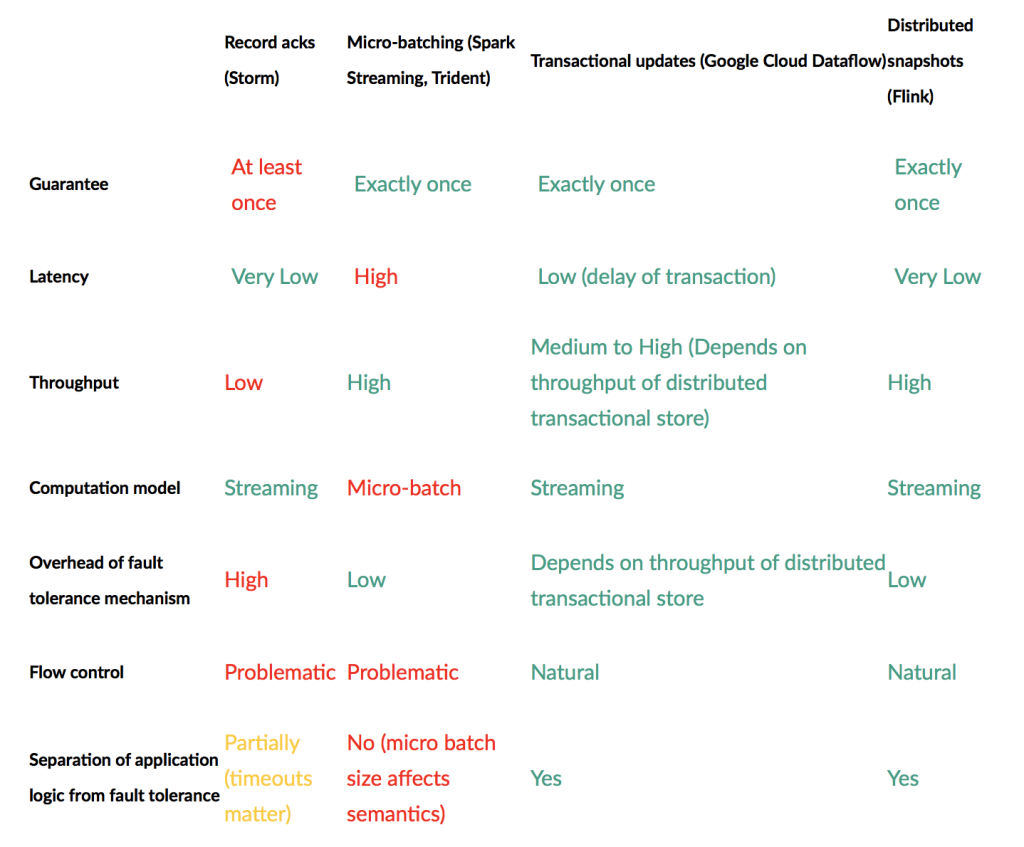
(以上資料取自https://data-artisans.com/blog/high-throughput-low-latency-and-exactly-once-stream-processing-with-apache-flink)
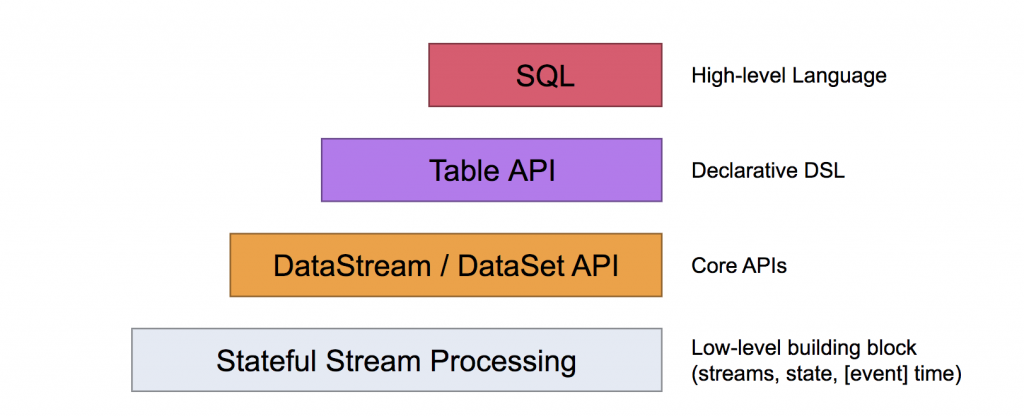
(以上資料取自https://ci.apache.org/projects/flink/flink-docs-release-1.6/concepts/programming-model.html)
從上圖來看, 底層處理資料的API分為DataStream和DataSet(分別是Streaming & Batch), 本系列文會以DataStream的應用和操作為主, 在系列文的最後如有時間的話再討論DataSet/SQL的使用。
本系列文主要以以下環境操作, 後期有使用其他工具或變動環境會在該篇文章進行補述
由於工作上的關係想對Apache Flink有更深入的了解, 以此順便記錄學習過程, 希望系列文章寫完之後能對Flink和Scala都能更駕輕就熟。


 iThome鐵人賽
iThome鐵人賽